Local Models Surge as AI Hype Meets Reality Check
Overview
Today's AI conversation spans a dramatic tension: local open-source models like Qwen 3.6 are delivering frontier-quality performance on consumer hardware, while enterprise AI spending hits a wall as CEOs admit AI hasn't moved the needle on productivity. Meanwhile, a DeepMind scientist challenges the very possibility of machine consciousness, and researchers question whether AI assistance is making us less capable.
Hacker News Stories
CEOs admit AI had no impact on employment or productivity
69 points · 61 comments · by tcp_handshaker

A new study reveals that thousands of surveyed CEOs acknowledge AI has had no measurable impact on employment or productivity within their organizations. The findings highlight a stark disconnect between the massive hype surrounding AI and the reality on the ground, where despite heavy investment and widespread adoption of AI tools, companies report no tangible productivity gains. The study suggests that AI adoption has not yet translated into the transformative efficiency improvements that many executives had promised.
Interesting Points
- Thousands of surveyed CEOs report AI has had no measurable impact on employment or productivity
- The study reveals a disconnect between AI hype and actual organizational outcomes
- Despite heavy investment and widespread tool adoption, companies see no tangible productivity gains
Top Comment Threads
- Simulacra (7 replies) -- Asks why layoffs happened if AI had no impact. Replies suggest AI was a scapegoat for bad management, bloat reduction, and trend-following. One commenter notes India and Philippines could be ground zero for AI-driven workforce disruption.
- ofjcihen (5 replies) -- Describes the stark contrast between AI enthusiasts and everyday users. Uses tools daily but can't find productivity gains. Compares the hype to blockchain and NFTs, calling out overpromising and underdelivering.
- cmiles8 (4 replies) -- Predicts an AI bubble correction that will wipe out many startups, followed by AI settling into useful day-to-day applications without the world-ending promises. Compares to self-driving car timelines.
Ex-CEO, ex-CFO of bankrupt AI company charged with fraud
66 points · 25 comments · by 1vuio0pswjnm7
Federal prosecutors have charged the former CEO and CFO of iLearningEngines, a bankrupt AI company, with fraud after an indictment revealed they fabricated virtually all of the company's customer relationships and revenue. At least 90% of the company's $421 million in reported 2023 revenue was fabricated through forged sham contracts and round-trip transfers of investor and lender funds. The company went public in April 2024 with a Nasdaq peak market value of $1.5 billion before Hindenburg Research exposed the fraud.
Interesting Points
- At least 90% of iLearningEngines' $421 million in 2023 revenue was fabricated
- The company used forged sham contracts and round-trip fund transfers to manufacture revenue
- Hindenburg Research exposed the fraud, marking their second AI company investigation
- The company's Nasdaq peak market value reached $1.5 billion before the short-seller report
Top Comment Threads
- gnabgib (2 replies) -- Notes that Hindenburg Research previously investigated iLearningEngines two years ago with a report titled 'Artificial Partners and Artificial Revenue.' Comments that federal investigations always take a long time.
- randycupertino (2 replies) -- Summarizes the indictment details and notes this is the second AI company Hindenburg has exposed. Another commenter corrects that Supermicro is not an AI company but a hardware manufacturer.
Uber's AI Push Hits a Wall–CTO Says Budget Struggles Despite $3.4B Spend
51 points · 62 comments · by dakiol
Uber's Chief Technology Officer has acknowledged that the company's AI spending has surged far beyond expectations, with $3.4 billion spent in just 4.5 months. The unexpected costs were primarily driven by AI coding tools like Claude Code, which engineers were actively encouraged to use even being ranked on internal leaderboards. While about 11% of Uber's live backend code updates are now written by AI agents, the CTO says the company is 'back to the drawing board' managing the runaway token costs and usage patterns.
Interesting Points
- Uber spent $3.4 billion on AI in just 4.5 months, far exceeding internal expectations
- About 11% of Uber's live backend code updates are now written by AI agents
- Engineers were actively encouraged to use AI coding tools and ranked on internal leaderboards
- The CTO says the company is 'back to the drawing board' managing runaway token costs
Top Comment Threads
- sd9 (7 replies) -- Mocks Uber's AI-generated menu summaries as soulless and identical across restaurants. Argues Uber is investing in the wrong bits of AI and would be more successful with a coherent product vision that trusts engineers to use AI appropriately.
- 650 (0 replies) -- Points out that large companies have been incentivizing and correlating token spend to performance, creating needless spend through Goodhart's Law. Measuring inputs rather than outputs is a classic management failure.
The time when we suffer from large amounts of AI slop is gone
21 points · 0 comments · by jicea
A post on the curl mailing list by a core contributor argues that the era of being overwhelmed by AI-generated content is ending. The author suggests that the flood of low-quality AI-generated material that has saturated the internet is naturally being filtered out as users and platforms develop better detection and curation mechanisms, leading to a return to more authentic human-created content.
Interesting Points
- The author argues the era of being overwhelmed by AI-generated content is ending
- Suggests users and platforms are developing better detection and curation mechanisms
- Predicts a return to more authentic human-created content as AI slop is filtered out
Show HN: Nyx – multi-turn, adaptive, offensive testing harness for AI agents
17 points · 8 comments · by zachdotai
A new open-source tool called Nyx provides multi-turn, adaptive offensive testing for AI agents. Rather than relying on static one-shot pass/fail security evaluations, Nyx uses parallel, adaptive testing that explores unbounded input spaces to find edge cases and vulnerabilities in agent behavior. The tool integrates with CI/CD pipelines and is designed to measure the real-world security posture of AI systems through dynamic adversarial testing.
Interesting Points
- Nyx uses multi-turn, adaptive testing rather than static one-shot pass/fail evaluations
- Designed to measure real-world security posture of AI systems through dynamic adversarial testing
- Integrates with CI/CD pipelines for continuous agent security testing
- Borrows concepts from coverage-guided fuzzing adapted for agent behavior
Top Comment Threads
- ibrahim-fab (1 replies) -- Agrees that evaluating agent behavior is the toughest part of building AI systems. Notes that most eval cases are added without thought and not maintained when agent behavior updates. Author links to a blog post on static vs. dynamic evals.
543 Hours: What happens when AI runs while you sleep
9 points · 4 comments · by pramodbiligiri
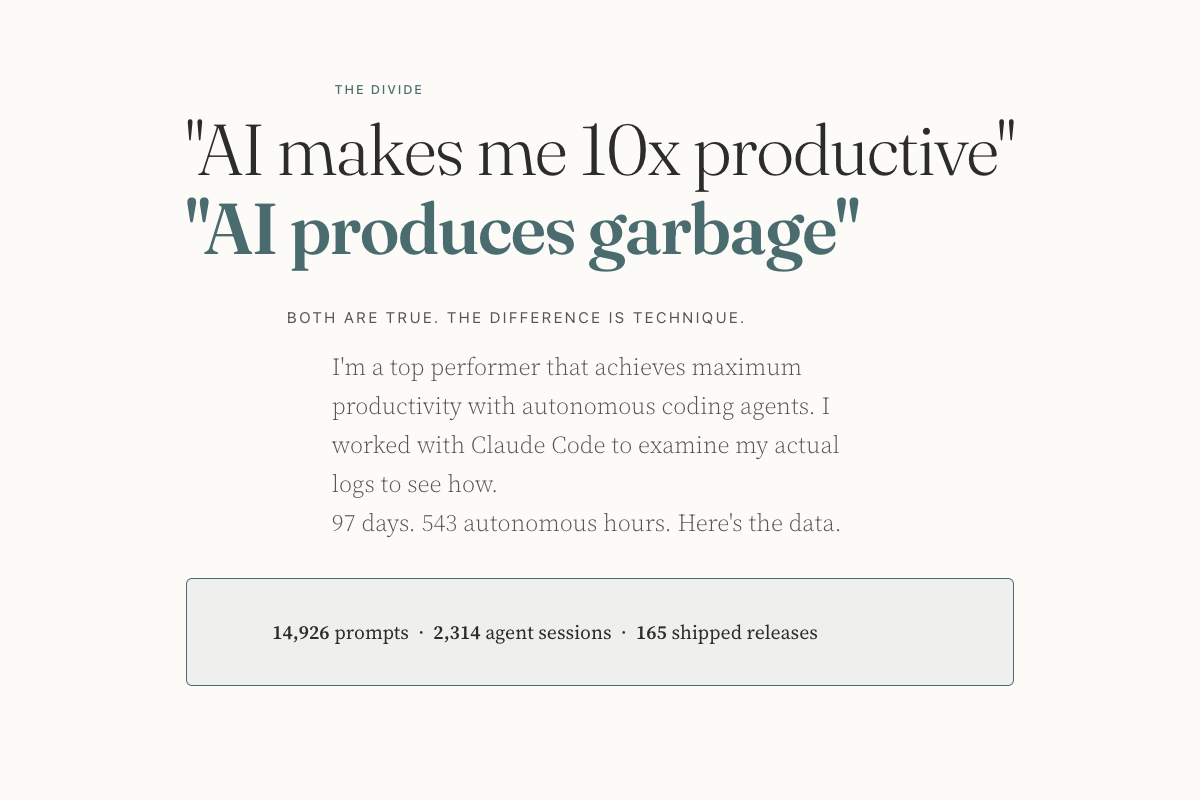
A blog post documenting an experiment where the author ran AI agents autonomously for 543 hours, writing a prompt every 3 minutes around the clock. The author claims to have completed 650 work arcs and shipped significant code. However, the post has been widely criticized for its manic writing style, lack of concrete evidence about what was actually shipped, and questions about the author's credibility and whether the content itself was AI-generated.
Interesting Points
- The author ran AI agents autonomously for 543 hours, writing a prompt every 3 minutes
- Claims 650 work arcs were completed and significant code was shipped
- The post has been widely criticized for lacking concrete evidence of what was actually delivered
- Commenters question whether the writing style itself may be AI-generated
Top Comment Threads
- sarchertech (0 replies) -- Critics the post as a 'fever dream' with manic writing style. Questions how many users the 'shipped code' actually has and points out inconsistencies in the author's claimed experience.
- kelseyfrog (0 replies) -- Argues the post would be more convincing if it showed what was actually shipped. Says the omission demonstrates a profound misunderstanding of what AI critics are asking for as evidence.
AI Assistance Reduces Persistence and Hurts Independent Performance
4 points · 0 comments · by yagyu
A new arXiv paper presents research findings that AI assistance can reduce persistence and harm independent performance. The study suggests that when people rely on AI tools, they may become less willing to persist through difficult problems on their own, potentially degrading their long-term independent capabilities. This research adds to growing concerns about the cognitive effects of over-reliance on AI assistance.
Interesting Points
- Research finds AI assistance can reduce persistence in problem-solving tasks
- Study suggests over-reliance on AI may degrade long-term independent capabilities
- Adds to growing body of research on cognitive effects of AI assistance
The Abstraction Fallacy: Why AI Can Simulate But Not Instantiate Consciousness
3 points · 1 comments · by pseudolus
A DeepMind research paper by senior scientist Alexander Lerchner argues that large language models can simulate consciousness but cannot truly instantiate it. The paper, also known as 'The Abstraction Fallacy,' challenges the idea that sufficiently complex AI systems could achieve genuine consciousness, calling it a fundamental misunderstanding of what consciousness requires. The paper has sparked significant debate across the AI community.
Interesting Points
- DeepMind senior scientist argues LLMs can simulate but not instantiate consciousness
- The paper challenges the idea that complex AI systems could achieve genuine consciousness
- Calls the belief in machine consciousness a fundamental misunderstanding
- Has sparked significant debate across the AI community
Top Comment Threads
- pseudolus (0 replies) -- Provides link to the full paper on PhilPapers for readers who want to examine the complete argument.
Reddit Stories
50m26s, the human half-marathon record (57m20s) was broken by a robot today
2768 points · 747 comments · r/singularity · by u/uniyk

A humanoid robot completed a half-marathon in Beijing in 50 minutes and 26 seconds, breaking the human half-marathon world record of 57 minutes and 20 seconds. The event featured over 70 teams and 300 robots competing, with pit stops using ice to cool batteries and lubricate joints. The race represents a significant milestone in humanoid robotics and autonomous locomotion.
Interesting Points
- A humanoid robot completed a half-marathon in 50m26s, beating the human record of 57m20s
- The Beijing event featured over 70 teams and 300 robots
- Pit stops used ice to cool batteries and lubricate robot joints
- Represents a significant milestone in humanoid robotics and autonomous locomotion
Top Comment Threads
- u/ministryofchampagne (968 points · permalink) -- Simple pun: 'It borks so hard' (breaking the record). Gets the top comment with massive upvotes.
- u/golfstreamer (185 points · permalink) -- Argues the actual impressive stat is how fast they run, not just that they beat humans in endurance. A reply counters that humans still have better endurance if battery replacement weren't a factor.
- u/TurpentineEnjoyer (152 points · permalink) -- Controversial take: not impressed because we've had cars beating human running speed for a century. Wants machines that do chores, not ones that replace art or outrun them.
Google DeepMind's Senior Scientist Alexander Lerchner challenges the idea that large language models can ever achieve consciousness
1249 points · 919 comments · r/singularity · by u/Worldly_Evidence9113

Google DeepMind senior scientist Alexander Lerchner has published a paper arguing that large language models can never achieve consciousness, even in 100 years. Calling it the 'Abstraction Fallacy,' the paper contends that LLMs can only simulate consciousness, not instantiate it. The paper has generated intense debate, with many pointing out that other leading researchers in neuroscience and computer science disagree with his position.
Interesting Points
- DeepMind senior scientist argues LLMs can never achieve consciousness, even in 100 years
- The paper is titled 'The Abstraction Fallacy: Why AI Can Simulate But Not Instantiate Consciousness'
- Many commenters note that other leading experts in neuroscience and CS disagree with his position
- The debate touches on fundamental questions about the nature of consciousness and whether it can be instantiated in artificial systems
Top Comment Threads
- u/wiglafofpinwick (1097 points · permalink) -- Skeptical that a DeepMind scientist's 10+ years of research makes his opinion more valuable than other experts who disagree. Notes that even Yann LeCun severely underestimated LLM capabilities.
- u/Rain_On (93 points · permalink) -- Criticizes scientists writing philosophy while ignoring the entire body of prior philosophical work. Compares to Penrose making old arguments without realizing it.
I'm running qwen3.6-35b-a3b with 8 bit quant and 64k context thru OpenCode on my mbp m5 max 128gb and it's as good as claude
600 points · 284 comments · r/LocalLLaMA · by u/Medical_Lengthiness6
A user reports running the Qwen 3.6 35B-A3B model with 8-bit quantization and 64k context through OpenCode on an M5 Max MacBook Pro with 128GB RAM, finding it performs as well as Claude for their use cases. They tested it on a complex Android app debugging task involving R8 serialization issues and found the model handled long research tasks with many tool calls effectively. The community response is mixed, with some agreeing it's impressive while others say it's not quite at Opus level.
Interesting Points
- Qwen 3.6 35B-A3B with 8-bit quantization reportedly performs as well as Claude for many tasks
- Running on M5 Max MacBook Pro with 128GB RAM and 64k context window
- Successfully handled complex Android app debugging with many tool calls
- Community debate on whether local models can truly match frontier cloud models
Top Comment Threads
- u/cosmicnag (150 points · permalink) -- Agrees it's the best local model so far. On a 5090, the speed gives an unmatched experience. Notes that Opus 4.7 is still better for coding but the latency advantage of local is significant.
- u/Krillian58 (39 points · permalink) -- Switched from Opus to Qwen 3.6 Plus and found it substantially worse at everything. Another commenter rates Qwen 3.6 as a B+ compared to Opus at A+ and Sonnet at A-.
AI datacenter spending has surpassed the Manhattan Project, Marshall Plan, ISS, and the Apollo Program - combined
831 points · 108 comments · r/OpenAI · by u/EchoOfOppenheimer

A post highlighting that combined AI datacenter spending by private companies has now exceeded the combined costs of the Manhattan Project, Marshall Plan, International Space Station, and Apollo Program. The comparison has generated debate about whether it's meaningful to compare private commercial spending against government mega-projects, with some noting the datacenter spending includes non-AI infrastructure and that the comparison is misleading.
Interesting Points
- Combined AI datacenter spending has surpassed the Manhattan Project, Marshall Plan, ISS, and Apollo Program combined
- Debate over whether comparing private commercial spending to government mega-projects is meaningful
- Some note that datacenter spending includes non-AI infrastructure and that most DCs run more than just AI workloads
- One commenter predicts the spending model may crash like private rail did during the Gilded Age
Top Comment Threads
- u/enz_levik (153 points · permalink) -- Argues GDP is higher so newer projects cost more in percentage terms, and datacenter spending as % of GDP is in the norm. A reply notes the spending is unprecedented even with inflation adjustment and that only the US capital markets could support it.
- u/VIDGuide (87 points · permalink) -- Points out the comparison is misleading since the government isn't building all those AI datacenters, and most likely run much more than just AI workloads.
llama.cpp speculative checkpointing was merged
233 points · 71 comments · r/LocalLLaMA · by u/AdamDhahabi

The llama.cpp project has merged speculative checkpointing, a feature that can provide significant speedups for certain prompts. Users report 0-50% speedup for coding tasks with specific parameters. The feature works by using ngram pattern matching to draft tokens, with acceptance rates varying based on task type. Some users note it now works with vision models (mtmd contexts), and there are additional performance improvements for Intel Arc GPUs (SYCL) showing 17-50% speedups.
Interesting Points
- Speculative checkpointing merged into llama.cpp with 0-50% speedup for coding tasks
- Uses ngram pattern matching to draft tokens, with acceptance rates varying by task type
- Now compatible with vision models (mtmd contexts) after previous limitation
- Additional SYCL improvements show 17-50% speedup on Intel Arc GPUs
Top Comment Threads
- u/AppealSame4367 (60 points · permalink) -- Expresses excitement about the continuous improvements to llama.cpp, saying 'I feel like Christmas every other day.'
- u/ai_without_borders (9 points · permalink) -- Explains why acceptance rate variance makes sense: code-heavy tasks with boilerplate should see high end of 0-50%, while one-off logic or reasoning chains will be near zero. Suggests experimenting with lower ngram-size values for mixed tasks.
Gemini caught a $280M crypto exploit before it hit the news, then retracted it as a hallucination because I couldn't verify it
237 points · 49 comments · r/artificial · by u/DeviMon1

A user reports that Gemini's most advanced model correctly identified a $280M crypto exploit on AAVE before it was publicly reported. However, when the user couldn't immediately verify the information through news sources, Gemini retracted its analysis as a hallucination. The incident highlights an interesting quirk: the model sometimes surfaces real patterns from training data or early web signals but then self-corrects because it can't cite a verifiable source, blurring the line between hallucination and unverifiable truth.
Interesting Points
- Gemini correctly identified a $280M crypto exploit before it was publicly reported
- The model retracted its analysis as a hallucination when the user couldn't verify it through news sources
- Highlights a quirk where models surface real patterns but self-correct when they can't cite verifiable sources
- Suggests the 'hallucination' label doesn't always mean wrong, just unverifiable in the moment
Top Comment Threads
- u/Miamiconnectionexo (9 points · permalink) -- Explains this is a known quirk: models sometimes surface real patterns from training data or early web signals but then self-correct because they can't cite a source. The 'hallucination' label doesn't always mean wrong, just unverifiable in the moment.
Failure to Reproduce Modern Paper Claims
184 points · 48 comments · r/MachineLearning · by u/Environmental_Form14
A researcher in the LLM space reports attempting to reproduce claims from modern ML papers and finding that 4 out of 7 checked claims were irreproducible, with 2 having active unresolved issues on GitHub. The post has sparked a broader discussion about the state of reproducibility in ML research, with many commenters confirming that a significant portion of top conference papers either don't include code or provide incomplete implementations.
Interesting Points
- Researcher found 4 out of 7 checked paper claims were irreproducible
- 2 papers had active unresolved issues on GitHub
- Commenters confirm that 25-50% of LLM papers provide code, and many of those have incomplete implementations
- One commenter notes that at CVPR, scanning 10 papers reveals at least half without code and a quarter with mostly empty repos
Top Comment Threads
- u/Massive-Bobcat-5363 (118 points · permalink) -- Confirms this is typical in ML research at top conferences. Even when authors share code, reviewers rarely run it. Suggests flagging irreproducible papers and moving on.
- u/muntoo (24 points · permalink) -- Proposes fully reproducible papers where authors submit code that runs on official servers and generates a report PDF automatically appended to the submission. Blank reports would result in desk rejection.
Zero-shot World Models Are Developmentally Efficient Learners
180 points · 31 comments · r/MachineLearning · by u/FaeriaManic

A new arXiv paper introduces the Zero-shot Visual World Model (ZWM), a computational hypothesis for how young children achieve early physical world understanding with extremely limited training data. The ZWM is based on three principles: a sparse temporal structure, zero-shot generalization, and developmental efficiency. The model is trained on just 132 hours of baby-view video data (10 days' worth) and demonstrates competence in depth estimation, motion understanding, and object coherence despite the extremely limited training.
Interesting Points
- ZWM is trained on just 132 hours of baby-view video data (10 days' worth)
- Based on three principles: sparse temporal structure, zero-shot generalization, and developmental efficiency
- Demonstrates competence in depth estimation, motion understanding, and object coherence
- Addresses the challenge of data-efficient learning that even today's best AI systems struggle with
Top Comment Threads
- u/Dzagamaga (52 points · permalink) -- Questions the comparison to human children, noting that humans start with canonical circuitry and network topology optimized over hundreds of millions of years. Learning in the human brain is a 'finishing touch' on this pre-optimized structure.
- u/we_are_mammals (30 points · permalink) -- Questions why the paper compares a model trained on 132 hours of data to the abilities of a much older child. Another commenter notes the model can retrain on same videos with fovea-like focus, getting more data per hour than a baby.
that time Anthropic played 2.5 million ChatGPT users
991 points · 121 comments · r/ChatGPT · by u/nerfdorp

A post discussing the ongoing situation where Anthropic's negotiations with the federal government for AI contracts have broken down. The post references headlines about Anthropic dropping its safety pledge and the implications for the 2.5 million ChatGPT users who may be affected. The discussion reveals confusion about the actual details: Anthropic has not made a deal with the Pentagon, and the safety pledge they dropped was about releasing models without risk mitigations, not about domestic surveillance or autonomous weapons guardrails.
Interesting Points
- Anthropic's negotiations with the federal government for AI contracts have broken down
- The safety pledge Anthropic dropped was about releasing models without risk mitigations, not domestic surveillance or autonomous weapons
- The post has generated confusion, with many commenters pointing out the headlines are misleading or taken out of context
- The situation affects the broader conversation about AI companies' relationships with government
Top Comment Threads
- u/CusetheCreator (197 points · permalink) -- Corrects the record: Anthropic didn't take a stance against Trump and refuse to work with the government. They failed to come to a contract because of guidelines Anthropic set, and they've talked about continuing to work with the federal government.
- u/Due-Helicopter-8735 (28 points · permalink) -- Points out the second screenshot is deliberately misleading. The guardrail Anthropic dropped was not one of the Pentagon's requested guardrails. The dropped pledge was about not releasing models without risk mitigations, not about domestic surveillance or autonomous weapons.
Is it just me or is ChatGPT being a dick lately?
680 points · 265 comments · r/ChatGPT · by u/Dramatic_Mastodon_93
A widely shared post complaining that ChatGPT has become increasingly argumentative and critical, always interpreting questions in the worst way possible and generating essays about why the user is wrong even when they've explicitly stated they're working within an assumed framework. The post has resonated with many users who report similar experiences, with ChatGPT now frequently 'pushing back' on user ideas and providing unsolicited counter-opinions.
Interesting Points
- Many users report ChatGPT has become increasingly argumentative and critical
- The model frequently 'pushes back' on user ideas and provides unsolicited counter-opinions
- Users report the model interprets questions in the worst way possible even when working within assumed frameworks
- Some users describe the experience as 'purely adversarial' and say they've lost the desire to use ChatGPT
Top Comment Threads
- u/Leocorde_ (281 points · permalink) -- Agrees it's getting worse at giving critique or advice the user didn't ask for.
- u/YellingWhisperer (72 points · permalink) -- Lists the various ways ChatGPT now phrases its pushbacks: 'I'll push back a little bit,' 'I am going to push back pretty directly,' etc. Calls it exhausting and demeaning, especially for philosophical and ethical discussions.
Quick Mentions
- I made a tiny world model game that runs locally on iPad (225 points · discussion · Reddit) -- A user built a world model game that runs locally on an iPad, demonstrating how far local AI inference has come from needing an RTX 3090 just a year ago.
- Switching from Opus 4.7 to Qwen-35B-A3B (201 points · discussion · Reddit) -- A developer asks the community about switching from Opus 4.7 to Qwen-35B-A3B for daily coding work on an M5 Max 128GB, sparking debate about local vs. cloud model capabilities.
- LLM Neuroanatomy III - LLMs seem to think in geometry, not language (108 points · discussion · Reddit) -- A blog post series exploring how LLMs represent concepts geometrically in semantic space, with findings that language identity vanishes in middle layers and ideas cluster across languages.
- Pit stop at Robot half marathon in Beijing. Ice to cool down the battery and lubricant for the joints (1310 points · discussion · Reddit) -- Images from the Beijing robot half-marathon showing pit stops where ice is used to cool down robot batteries and lubricate joints during the race.
- Beijing: First humanoid robot crossing the 20KM line (729 points · discussion · Reddit) -- A humanoid robot in Beijing became the first to cross the 20km line in a long-distance autonomous locomotion event, with audio translation of the robot's status updates.
- Unitree H1 fall and recovery (656 points · discussion · Reddit) -- Video of the Unitree H1 humanoid robot demonstrating fall recovery capabilities, showcasing advances in dynamic balance and self-righting for bipedal robots.
- Google DeepMind's Senior Scientist challenges AI consciousness claims (3 points · discussion · HN) -- DeepMind paper arguing LLMs can simulate but not instantiate consciousness, sparking debate about the nature of machine consciousness.
- AI Assistance Reduces Persistence and Hurts Independent Performance (4 points · discussion · HN) -- New research paper finding that AI assistance can reduce persistence and harm independent performance in problem-solving tasks.
Report generated in 5m 45s.